

Auto Correlation -UniSAR
Backbone
AutoFormer
class SmalModel(nn.Module):
def __init__(self, cfg):
super().__init__()
auto_correletion = AutoCorrelation(
factor=1, # used for top_k prediction thing
attention_dropout=0.05,
output_attention=True,
scale=None, # does nothing (never used)
mask_flag=True, # does nothing (never used)
)
self.autocorr_layer = AutoCorrelationLayer(
correlation=auto_correletion,
d_model=cfg.d_model,
n_heads=cfg.n_heads,
d_keys=None) # Why we not use it? who knows
def forward(self, x, attn_mask=None):
x = self.autocorr_layer(x,x,x, attn_mask)
return x
# return self.out_projection(out), attn)
# the shape of curve data is:
# 32*1810*1 batch*size * seq_len * d_model
# (note) if phase == -1, it is just padded data.
UniSAR:Modeling User Transition Behaviors between Search and Recommendation
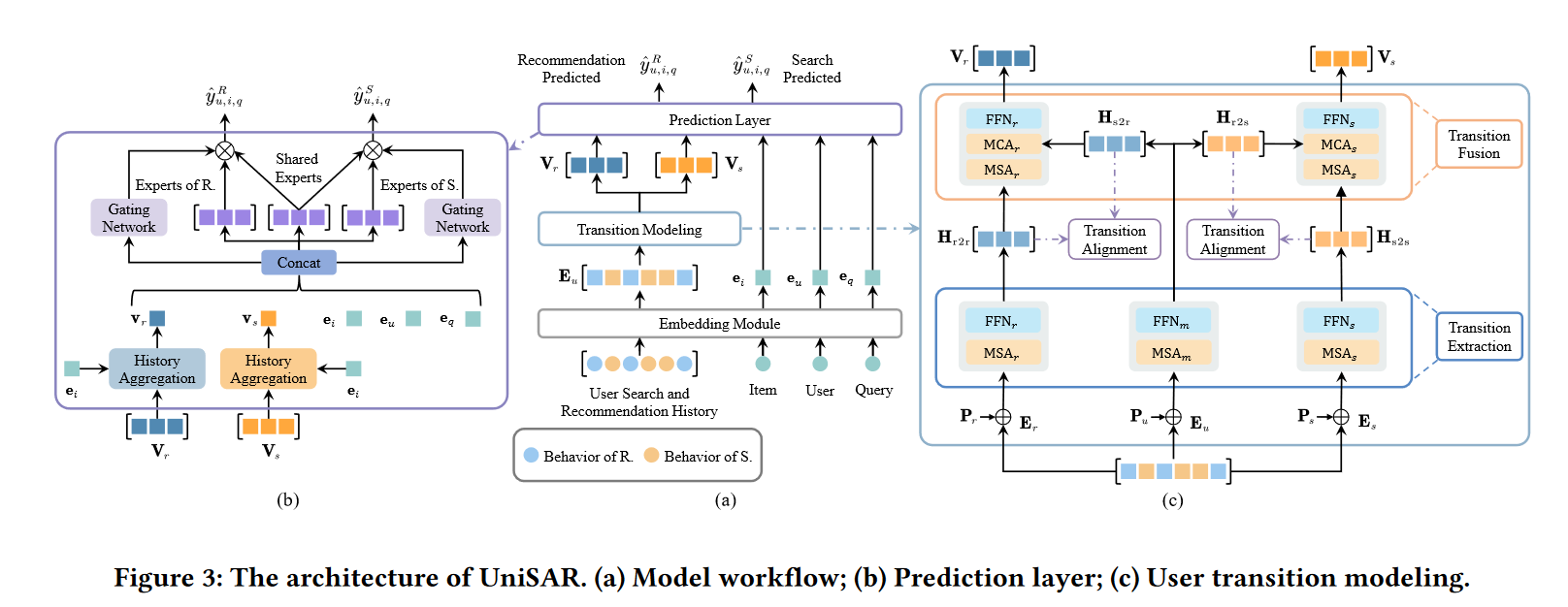
[!y]
- 为什么要用msa,多头代码怎么实现?
- rec_his_ts src_session_his_ts 的ts是什么意思?
- 为什么ac 4.1部分要相加?
- pos_items是什么意思
Next Point-of-Interest Recommendation
[!r]
ac最后mp mc要加权最后一维度? 结果是RN还是RL [AutoMTN/model.py at main · bilibili55/AutoMTN
(https://github.com/bilibili55/AutoMTN/blob/main/model.py)
A:
4.4 Attention Predictor 模块总结
在 Attention Predictor 模块中,模型通过注意力机制计算候选 POI 的最终预测值,具体步骤如下:
1. POI 和类别嵌入
首先,模型从 POI 和类别序列中获取候选 POI 的嵌入:
- POI 嵌入:$$ E(L) = {e_{l1}, e_{l2}, \ldots, e_{l|L|}} \in \mathbb{R}^{|L| \times d} $$
- 类别嵌入:$$ E(C) = {e_{c1}, e_{c2}, \ldots, e_{c|C|}} \in \mathbb{R}^{|C| \times d} $$
其中,$$ |L| $$ 是候选 POI 的数量,$$ |C| $$ 是类别的数量,$$ d $$ 表示嵌入的维度。
2. 距离矩阵 $$ D $$ 的引入
距离矩阵 $$ D \in \mathbb{R}^{N \times |L|} $$ 表示输入序列中的 POI 与候选 POI 之间的空间距离。在 Attention Predictor 中,这个距离矩阵用于帮助模型捕捉 POI 的空间关系:
- 转置矩阵 $$ D^T $$ 用于与 POI 嵌入相结合。
- 从上下文来看,这里的
+操作更可能是直接逐元素求和,而非拼接操作。3. 候选 POI 的注意力权重计算
候选 POI 的预测值通过以下公式得到:
- Softmax 操作($$\text{SM}()$$):对输入矩阵的每一列(即时间步维度)执行 softmax 操作,得到候选 POI 的归一化权重。
- 加权求和操作($$S()$$):在 softmax 权重的基础上,对 $$ E(L) $$ 的每个元素进行加权求和,生成最终的 POI 评分。
4. 生成最终的 L 维输出
经过上述步骤,模型输出一个 L 维向量 $$ Y_P $$,表示每个候选 POI 的最终预测评分,用于推荐排序。
总结
- 嵌入生成:POI 和类别嵌入通过模型生成,用于后续的注意力计算。
- 距离信息结合:距离矩阵 $$ D^T $$ 与嵌入逐元素求和,融合距离影响。
- 加权和生成:对候选 POI 执行 softmax,加权求和得到最终的评分向量。
这一 Attention Predictor 设计能够有效捕捉 POI 和类别序列中的空间和时间关系,帮助模型生成准确的 POI 推荐结果。
数据集
KuaiSAR A Unified Search And Recommendation Dataset
[!y]
- dataset/rec_train.pkl里的 all_his(A:rec_his + src_his)和g_s_id neg_items都是什么意思
- src_session_his 和 src_his的区别是什么
- data\KuaiSAR\vocab\src_session_vocab.txt的pos_items是什么意思
user_map_vocal:
| user_id | The ID of the user. | int64 | 6302 |
|---|---|---|---|
| search_active_level | Search activity level of the user. | int64 | 1 |
| rec_active_level | Recommendation activity level of the user. | int64 | 1 |
| onehot_feat1 | An encrypted feature. Range: {0, 1, 2} | int64 | 1 |
| onehot_feat2 | An encrypted feature. Range: {0, 1, …, 7} | int64 | 3 |
item_map_vocal:
[!x]
key : caption value : [251953 174047 317213 14 14 186670 346086 14 165570 346086
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0] single length : 50 length : 673415
key : first_level_category_id value : 21 length : 673415
key : second_level_category_id value : 182 length : 673415
query_vocab:
[!x] max k.length = 15
key : [394909] k.length : 1
key : [389043, 244825, 14, 296523, 250448, 171131, 163779, 14, 8304, 157721, 123199, 39, 394909, 40, 346924, 225319, 14, 198253, 306440, 289815, 14, 14, 14, 8304, 227444, 290791, 39, 98896, 40, 14] k.length : 30
key : [14, 250448, 213286, 185884, 14, 292241, 227356] k.length : 7
key : [14, 355568, 14, 227444, 380340, 14, 14, 152666, 346834, 288381, 144853, 14, 8304, 227444, 380340, 39, 35318, 40, 14, 8304, 227444, 290791, 39, 98896, 40, 14, 8304, 227444, 318781, 39, 98858, 40, 14] k.length : 33
key : [302198, 145714, 183045, 14, 130474, 14, 130474, 179064, 183045, 351801, 281000, 14, 302198, 183045] k.length : 14
[!g]
这里的query和搜索历史的关键字是一一对应的
src_session_vocab:
[!x]
key : keyword value : [[ 0 0 0 ... 0 0 0]
...
[210348 390569 344053 ... 0 0 0]] value.len : 404345key : pos_items value : [[ 0 0 0 0 0]
[ 6357 147704 0 0 0]
...
[ 0 0 0 0 0]] value.len : 404345
user_map_vocab:
[!x]
key : onehot_feat1 value : [2 7 7 ... 6 7 2] value.length : 22700
key : onehot_feat2 value : [2 1 2 ... 2 2 1] value.length : 22700
key : search_active_level value : [6 4 4 ... 3 0 3] value.length : 22700
key : rec_active_level value : [0 3 3 ... 0 0 0] value.length : 22700
user_vocab:
key : 0
value : {'user_id': 0, 'onehot_feat1': 2, 'onehot_feat2': 2,
'search_active_level': 6, 'rec_active_level': 0,
'rec_his':[480591, 261156, 485900, 153642, 427958, 385910, 535036, 66318, 529255, 667326, 361825, 540260, 603613, 374491, 102888, 250833, 480173, 524110]
'rec_his_ts': [1684747829334.0, 1684757019728.0, 1684760057971.0, 1684760191517.0, 1684760841193.0, 1684762951191.0, 1684762951191.0, 1684763427261.0, 1684763427261.0, 1684763922747.0, 1684763922747.0, 1684765385756.0, 1684766957830.0, 1684766957830.0, 1684767463950.0, 1684767463950.0, 1684767872672.0, 1684836429201.0],
'src_session_his': [3101, 3407, 3430, 7237, 17541, 17581, 17638, 17724, 17839, 18358, 36906, 37033, 37094, 304224, 308970, 309240, 309823, 310765, 320537, 320750, 321128, 321138, 321977, 321996, 322092, 324453, 331324, 331600, 331620, 332778, 333123, 333153, 337743, 337918, 343834, 344183, 345528],
'src_session_his_ts': [1684749383217.0, 1684750006344.0, 1684750041291.0, 1684755421701.0, 1684766115854.0...]
'src_his_ts': [1684749383217.0, 1684750006344.0, 1684750041291.0, 1684755421701.0, ...]
'src_his_query': [[190514, 239637, 200550], [190514, 239637, 200550], [247009],
'all_his': [480591, 0, 0, 0, 334380,...]
'all_his_ts': [1684747829334.0, 1684749383217.0, 1684750006344.0,...]
'all_his_query': [0, [190514, 239637, 200550], [190514, 239637, 200550], [247009],...] #第一个0是rec的query默认0
Python 常用api总结
字典生成式
{k: expression for k, v in iterable}
{
k: torch.from_numpy(v).to(self.device)
for k, v in user_map_vocab.items()
}
# 假设 user_map_vocab 是一个包含键值对的列表
user_map_vocab = [('a', np.array([1,2,3])), ('b', np.array([4,5,6]))]
self.user_map_vocab = {
k: torch.from_numpy(v).to(self.device)
for k, v in user_map_vocab #umv这个list每次遍历返回2个值,给k和v
}
items() 遍历字典的key和val
items()` 是 **Python 字典类**(`dict`)的一个方法。它用于返回字典中所有**键值对**组成的视图对象,每个键值对都表示为一个**元组** `(key, value)
for key, value in my_dict.items(): print(f"Key: {key}, Value: {value}")
enumerate() 遍历可迭代对象
enumerate() 的作用是在迭代一个可迭代对象时,生成一对由索引和元素组成的二元组(index, element),让你在遍历的时候可以同时访问到元素的索引和对应的值。
基本用法
假设我们有一个列表:
user_map_vocab = ['apple', 'banana', 'cherry']
如果直接用 for 循环遍历这个列表:
for item in user_map_vocab:
print(item)
输出会是:
apple
banana
cherry
此时,循环只会输出列表中的元素,但没有提供元素的索引。
如果使用 enumerate(),你可以同时获得索引和对应的值:
for idx, item in enumerate(user_map_vocab):
print(f"Index: {idx}, Value: {item}")
输出结果:
Index: 0, Value: apple
Index: 1, Value: banana
Index: 2, Value: cherry
from .Runner import *
from .Runner import * 是 Python 中的一个导入语句,主要用于从当前包中的 Runner 模块导入所有的可用内容(函数、类、变量等)。
1. 语法说明
.(点号)表示当前包,也就是当前模块的所在包。from .是一种相对导入,表示从当前模块的同一级目录下导入其他模块。Runner是当前包中的一个模块。你希望从这个模块中导入内容。*表示导入模块中的所有公共内容,包括函数、类、变量等。但只会导入那些不以下划线开头的内容,默认情况下不会导入以_开头的私有变量或函数。
global前缀
x = 10 # 全局变量
def modify_global():
global x # 声明要使用全局变量 x
x = 5 # 修改全局变量 x 的值
print(x)
modify_global()
print(x) # 输出 5,说明全局变量的值已经被修改
os.path.join() 拼接地址
local_path = 'data\KuaiSAR'
user_map_vocab = os.path.join(local_path,'vocab/user_vocab_np.pkl') # 这里第二个参不用'/vocab/user_vocab_np.pkl'
Comments 12 条评论
戳一下〰️
@798296686 我喜欢你❤️
@Cher112 这是一条私密评论
@Cher112 这是一条私密评论
@798296686 这是一条私密评论
@798296686 这是一条私密评论
这是一条私密评论
这是一条私密评论
这是一条私密评论
这是一条私密评论
这是一条私密评论
这是一条私密评论